
一,本文宗旨:
在一个集群中,一定会有代理服务器,如果只有单点的代理服务器,一旦它出现宕机,整个集群将失效!!!所有我们要避免出现这样的问题
二,实现方式:
keepalived服务介绍
官网:http://www.keepalived.org/
keepalived起初是为了LVS设计的,专门用来监控集群系统中的每个服务器节点状态,后来又加入了VRRP的功能,VRRP是虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)。VRRP出现的目的就是为了解决静态路由出现的单点故障问题,它能保证网络的不间断,稳定的运行。
keepalived的2大用途:
failover和health check
A.failove功能:实现LB MASTER主机和Backup主机之间的故障转移和自动切换
这是针对有2个负载均衡器同时工作而采取的故障转移措施。当主负载均衡器实效或者出现故障的时候,备份负载均衡器将自动接管主负载均衡器的所有工作;一旦主负载均衡器故障修复,它就会重新接管之前的业务。
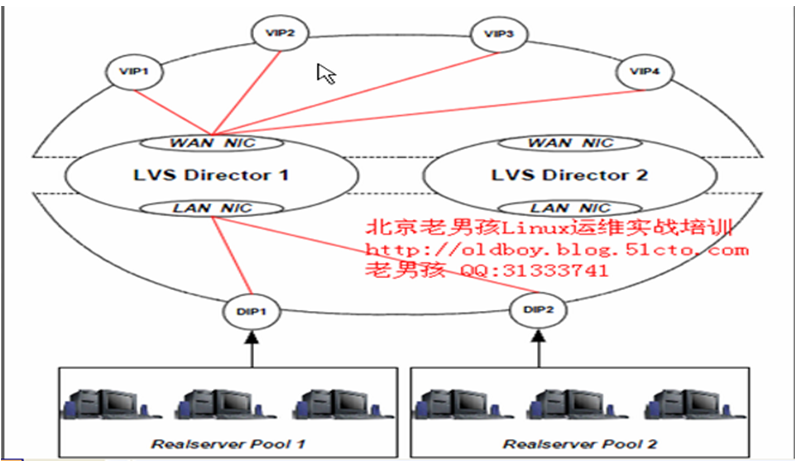
keepalived集群正常工作的双主架构图
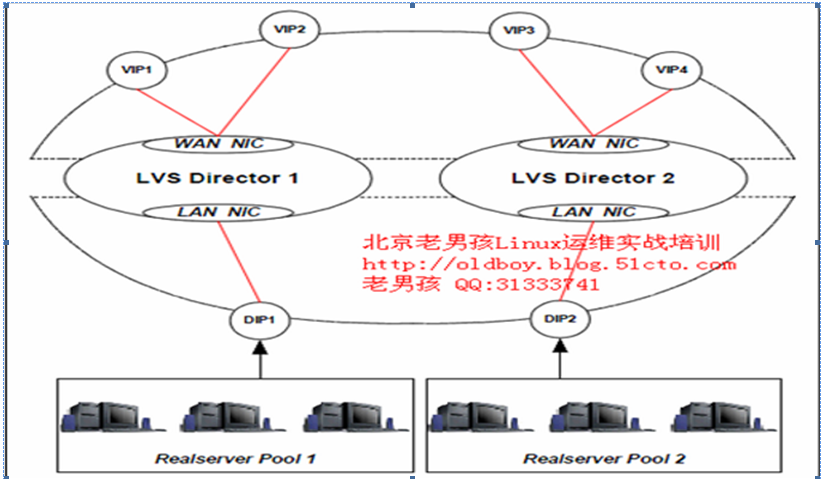
keepalived集群LVS director2宕机状态
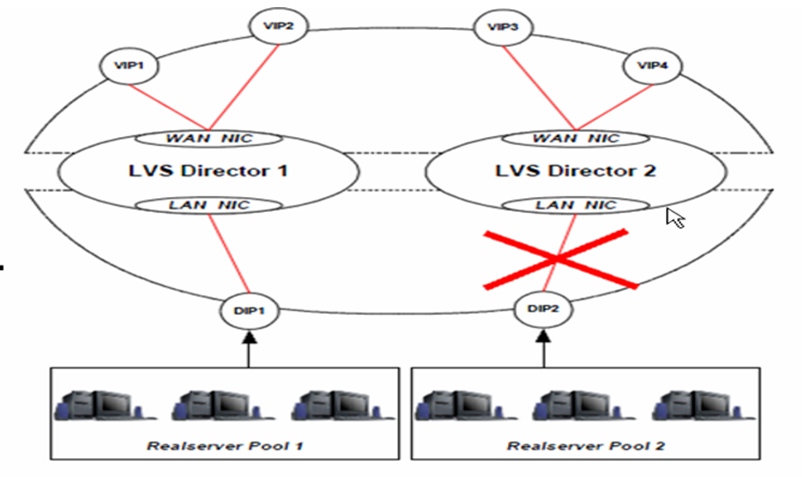
keepalived集群DIP2 takeover
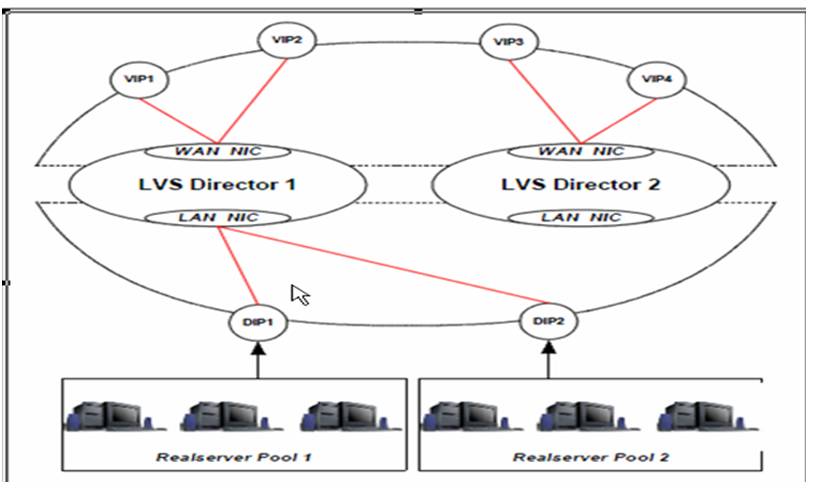
keepalived集群takeover后正常工作架构
B.health check功能:
检测web服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的web服务器从系统中剔除,当web服务器工作正常后Keepalived自动将web服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的web服务器
PS:由于nginx作为代理服务器已经用nginx_upstream_check_module模块实现了后端web站点的实时健康检查,所以这里就不用keepalived的健康检查了!!!
keepalived故障切换转移原理介绍
keepalived director之间的故障切换转移,是通过VRRP协议来实现的
在keepalived director正常工作的时候,主director节点会不断的向备份节点广播心跳消息,用于告诉备份节点自己还活着,当主节点发生故障时,备份节点就无法检测到主节点的心跳,进而调用自身的接管程序,接管主节点的ip资源和服务。而当主节点恢复时,备份节点就会释放主节点故障时自身接管的ip资源和服务,恢复到原来自身的备份角色。
三,具体实现步骤:
A.环境准备
| 外部公网IP地址 | – | 角色 | 备注 |
| eth0:192.168.0.61 | – | Nginx_LB_master | 主LB;对外提供服务的vip为eth0:0 192.168.0.250 ==》123.com |
| eth0:192.168.0.62 | – | Nginx_LB_backup | 备LB |
| eth0:192.168.0.60 | – | RS1(真实服务器) | nginx,提供web服务 |
| eth0:192.168.0.59 | – | RS2(真实服务器) | nginx,提供web服务 |
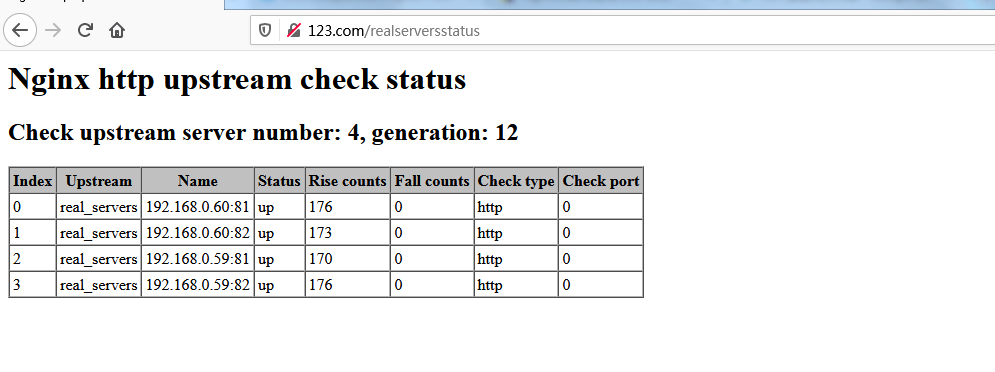
条件:
1)两台调度器都要开启nginx+keepalived
2)两台real server的nginx的web服务要正常运行
目标:
1)正常情况下,主LB要为2台RS服务器提供http负载均衡服务;
2)当主LB宕机的时候 ,备LB接管主LB提供负载均衡服务;主LB恢复的时候,备LB恢复原来的角色
PS:nginx作为代理服务器和web服务器的安装部署就不赘述了!!!可以参考:https://teddylu.xyz/blog/4398.html。
下面重点讲述keepalived的安装部署及配置
B.安装keepalived
wget https://www.keepalived.org/software/keepalived-2.2.2.tar.gz
tar xf keepalived-2.2.2.tar.gz
cd keepalived-2.2.2
./configure --prefix=/application/keepalived-2.2.2
make
make install
#将keepalived源码包中的启动脚本文件拷贝到系统的启动目录中
cp /root/keepalived-2.2.2/keepalived/etc/init.d/keepalived /etc/init.d/
chmod 700 /etc/init.d/keepalived
#创建keepalived的配置文件的目录并将其放入
mkdir /etc/keepalived
cp /application/keepalived-2.2.2/etc/keepalived/keepalived.conf /etc/keepalived/
service keepalived start
keepalived正常运行后,会启动3个进程,其中一个是父进程,负责监控其子进程。一个是vrrp子进程,另外一个是checkers子进程。
[root@lb_master keepalived-2.2.2]# ps -ef|egrep keepalived
root 69675 1 0 16:09 ? 00:00:00 /application/keepalived-2.2.2/sbin/keepalived -D
root 69676 69675 0 16:09 ? 00:00:00 /application/keepalived-2.2.2/sbin/keepalived -D
root 69677 69675 0 16:09 ? 00:00:00 /application/keepalived-2.2.2/sbin/keepalived -D
主LB的keepalived的配置文件:
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 [email protected]
6 [email protected]
7 [email protected]
8 }
9 notification_email_from [email protected]
10 smtp_server 127.0.0.1
11 smtp_connect_timeout 30
12 router_id LB_master
13 vrrp_skip_check_adv_addr
14 vrrp_strict
15 vrrp_garp_interval 0
16 vrrp_gna_interval 0
17 }
18
19 vrrp_instance VI_1 {
20 state MASTER
21 interface eth0
22 virtual_router_id 51
23 priority 150
24 advert_int 1
25 authentication {
26 auth_type PASS
27 auth_pass 1111
28 }
29 virtual_ipaddress {
30 192.168.0.250
31 }
32 }
33
备LB的keepalived的配置文件
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 [email protected]
6 [email protected]
7 [email protected]
8 }
9 notification_email_from [email protected]
10 smtp_server 127.0.0.1
11 smtp_connect_timeout 30
12 router_id LB_backup
13 vrrp_skip_check_adv_addr
14 vrrp_strict
15 vrrp_garp_interval 0
16 vrrp_gna_interval 0
17 }
18
19 vrrp_instance VI_1 {
20 state BACKUP
21 interface eth0
22 virtual_router_id 51
23 priority 100
24 advert_int 1
25 authentication {
26 auth_type PASS
27 auth_pass 1111
28 }
29 virtual_ipaddress {
30 192.168.0.250
31 }
32 }
keepalived的主LB和备LB的配置文件的区别对比
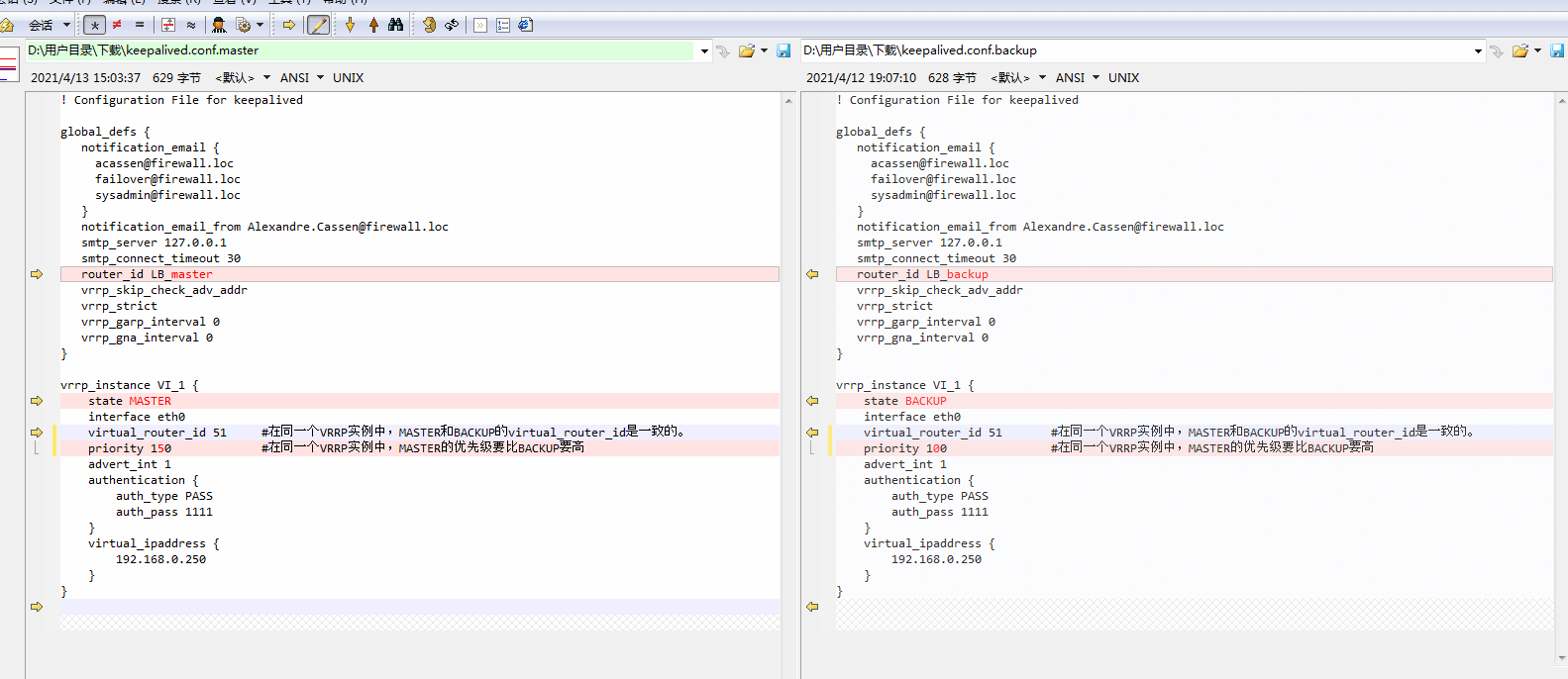
提示:
1)keepalive不是以别名的方式而是以辅助ip的形式添加VIP的,用ifconfig无法看到,所以要使用ip add命令来查看VIP是否有被添加上
2)在实际的生产环境下,可能会有多个VIP,通常不同的VIP会对应不同的应用服务,比如博客,论坛等。这个时候可以采用多实例来实现。
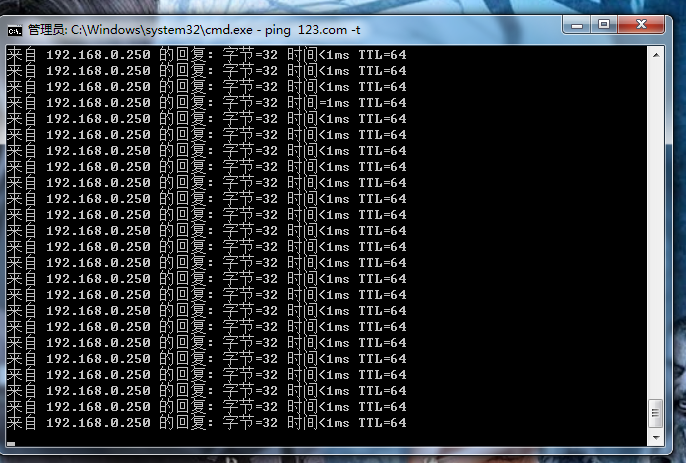
当设置好keepalive配置文件之后,开启keepalive,并查看VIP是否有正确添加地在主负载均衡器上。
[root@lb_master ~]# ip addr|grep 192.168.0.250
inet 192.168.0.250/32 scope global eth0
[root@lb_backup ~]# ip addr|grep 192.168.0.250
[root@lb_backup ~]#
结论:
VIP是连通的,VIP 192.168.1.250也已经正确地添加到主负载均衡器上了。
测试:
现在模拟主负载均衡器宕机,看看备份负载均衡器是否会接管
要使主LB宕机,可以关闭keepalive,或者直接系统关机
我用关闭keepalive,来演示:
master:
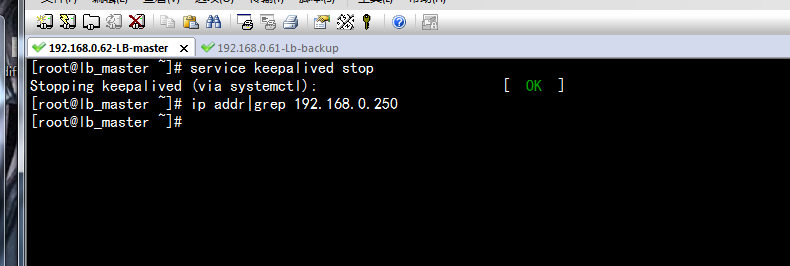
backup:
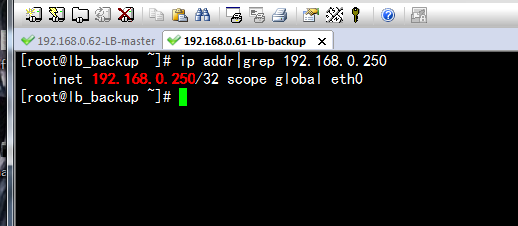
再看看VIP是否还是连通的
结论:
VIP还是连通的,VIP 192.168.1.250也及时地由备份负载均衡器接管了。然后,重新启动master的keepalived,发现vip又重新绑定到了master机器上!!!
四,生产环境下出现的问题及解决办法:
问题描述:解决nginx进程和keepalived不同时存在问题
模拟故障:在主LB上暂停nginx服务,看看备LB是否接管
master的情况
[root@lb_master conf]# /application/nginx-1.19.9/sbin/nginx -s stop
[root@lb_master conf]# ip addr|grep 250
inet 192.168.0.250/32 scope global eth0
backup的情况
[root@lb_backup conf]# ip addr|grep 250
[root@lb_backup conf]#
结论:当主LB的nginx进程不存在的时候,备LB是不会接管的!!!
keepalived是通过检测keepalived进程是否存在判断服务器是否宕机,如果keepalived进程在但是nginx进程不在了那么keepalived是不会做主备切换,所以我们需要写个脚本来监控nginx进程是否存在,如果nginx不存在就将keepalived进程杀掉。
解决办法:
在主LB上需要编写对nginx进程检测脚本(check_if_nginx_process_exist.sh ),判断nginx进程是否存在,如果nginx不存在尝试重启nginx,若无法启动,就将keepalived进程杀掉,check_if_nginx_process_exist.sh 内容如下:
1 #!/bin/bash
2 A=`ps -C nginx --no-header |wc -l`
3 if [ $A -eq 0 ];then
4 /application/nginx-1.19.9/sbin/nginx
5 sleep 3
6 if [ `ps -C nginx --no-header|wc -l` -eq 0 ]; then
7 killall keepalived
8 fi
9 fi
将check_nginx.sh拷贝至/etc/keepalived下,
脚本测试:
将nginx停止,将keepalived启动,执行脚本:sh /etc/keepalived/check_if_nginx_process_exist.sh
修改主LB的keepalived.conf
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 [email protected]
6 [email protected]
7 [email protected]
8 }
9 notification_email_from [email protected]
10 smtp_server 127.0.0.1
11 smtp_connect_timeout 30
12 router_id LB_master
13 vrrp_skip_check_adv_addr
14 vrrp_strict
15 vrrp_garp_interval 0
16 vrrp_gna_interval 0
17 }
18 vrrp_script check_nginx {
19
20 script "/etc/keepalived/check_if_nginx_process_exist.sh"
21 interval 3
22 weight -20
23
24 }
25
26 vrrp_instance VI_1 {
27 state MASTER
28 interface eth0
29 virtual_router_id 51
30 priority 150
31 advert_int 1
32 authentication {
33 auth_type PASS
34 auth_pass 1111
35 }
36
37 track_script {
38 check_nginx
39 }
40 virtual_ipaddress {
41 192.168.0.250
42 }
43 }
修改后重启keepalived
接着看下面这段配置,这段配置的意思是,每隔2秒中去执行/etc /keepalived /check_if_nginx_process_exist.sh脚本一次,这项检查从开始便一直进行,interval表示间隔时间,weight -20的意思是,脚本执行成功后把当前节点的优先级降低20。
| vrrp_script chk_nginx { script “/etc/keepalived/nginx_check.sh” interval 2 weight -20 } |
测试
回到负载均衡高可用的初始状态,保证主、备上的keepalived、nginx全部启动。
停止主LB的nginx服务
这个就不上图解析了!!!很简单的测试!!!
延伸:
Keepalived中Master和Backup角色选举策略
在Keepalived集群中,其实并没有严格意义上的主、备节点,虽然可以在Keepalived配置文件中设置“state”选项为“MASTER”状态,但是这并不意味着此节点一直就是Master角色。控制节点角色的是Keepalived配置文件中的“priority”值,但并它并不控制所有节点的角色,另一个能改变节点角色的是在vrrp_script模块中设置的“weight”值,这两个选项对应的都是一个整数值,其中“weight”值可以是个负整数,一个节点在集群中的角色就是通过这两个值的大小决定的。
在一个一主多备的Keepalived集群中,“priority”值最大的将成为集群中的Master节点,而其他都是Backup节点。在Master节点发生故障后,Backup节点之间将进行“民主选举”,通过对节点优先级值“priority”和““weight”的计算,选出新的Master节点接管集群服务。
在vrrp_script模块中,如果不设置“weight”选项值,那么集群优先级的选择将由Keepalived配置文件中的“priority”值决定,而在需要对集群中优先级进行灵活控制时,可以通过在vrrp_script模块中设置“weight”值来实现。下面列举一个实例来具体说明。
假定有A和B两节点组成的Keepalived集群,在A节点keepalived.conf文件中,设置“priority”值为100,而在B节点keepalived.conf文件中,设置“priority”值为80,并且A、B两个节点都使用了“vrrp_script”模块来监控nginx服务,同时都设置“weight”值为10,那么将会发生如下情况:
在两节点都启动Keepalived服务后,正常情况是A节点将成为集群中的Master节点,而B自动成为Backup节点,此时将A节点的nginx服务关闭,通过查看日志发现,并没有出现B节点接管A节点的日志,B节点仍然处于Backup状态,而A节点依旧是Master状态,在这种情况下整个HA集群将失去意义。
1. “weight”值为正数时
2. “weight”值为负数时
参考:http://www.uml.org.cn/zjjs/201808214.asp